Code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.formula.api as smf
rng = np.random.default_rng(3579)Source: PoissonExample/poisson_regression.Rmd
This example simulates count data from a log-linear Poisson regression and then contrasts it with overdispersed negative-binomial data. The Python port uses statsmodels GLM families and NumPy simulation.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.formula.api as smf
rng = np.random.default_rng(3579)n = 100
x = rng.uniform(-2, 2, n)
a = 1
b = 2
linpred = a + b * x
mu = np.exp(linpred)
y = rng.poisson(mu)
fake = pd.DataFrame({"x": x, "y": y})
fake.head()| x | y | |
|---|---|---|
| 0 | -0.023494 | 5 |
| 1 | 0.031250 | 6 |
| 2 | -1.093270 | 0 |
| 3 | -0.229920 | 1 |
| 4 | -1.595141 | 0 |
The R original uses:
stan_glm(y ~ x, family=poisson(link="log"), data=fake)The maximum-likelihood version is:
fit_fake = smf.glm("y ~ x", data=fake, family=sm.families.Poisson()).fit()
fit_fake.summary()| Dep. Variable: | y | No. Observations: | 100 |
|---|---|---|---|
| Model: | GLM | Df Residuals: | 98 |
| Model Family: | Poisson | Df Model: | 1 |
| Link Function: | Log | Scale: | 1.0000 |
| Method: | IRLS | Log-Likelihood: | -179.15 |
| Date: | Sun, 31 May 2026 | Deviance: | 101.79 |
| Time: | 23:04:39 | Pearson chi2: | 102. |
| No. Iterations: | 6 | Pseudo R-squ. (CS): | 1.000 |
| Covariance Type: | nonrobust |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 1.0353 | 0.071 | 14.670 | 0.000 | 0.897 | 1.174 |
| x | 1.9758 | 0.051 | 38.759 | 0.000 | 1.876 | 2.076 |
xgrid = np.linspace(-2.5, 2.5, 300)
eta_hat = fit_fake.params["Intercept"] + fit_fake.params["x"] * xgrid
fig, ax = plt.subplots()
ax.plot(xgrid, np.exp(eta_hat), color="black", label="fitted mean")
ax.scatter(fake.x, fake.y, s=24, alpha=0.75)
ax.set_ylim(-1, 200)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_title("Simulated data from Poisson regression")
ax.legend(frameon=False)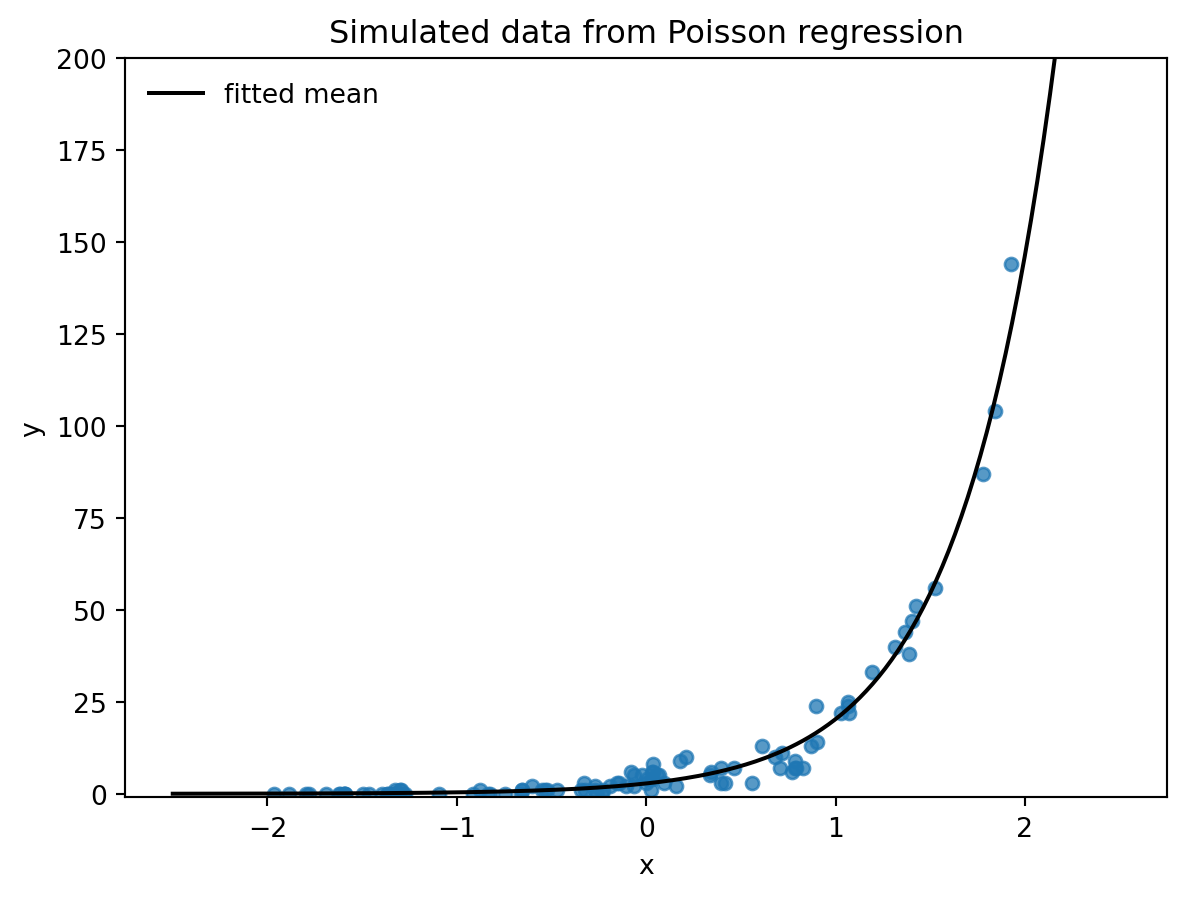
The R example uses MASS::rnegbin(n, mu, theta=phi). With that parameterization, variance is
[ (Y) = + ^2 / . ]
Small phi means heavy overdispersion; large phi approaches the Poisson.
def rnegbin_mu_phi(rng, mu, phi):
# NumPy negative_binomial uses number of successes r and success probability p,
# with mean r(1-p)/p. Set r=phi and p=phi/(phi+mu).
p = phi / (phi + mu)
return rng.negative_binomial(phi, p)
phi_grid = [0.1, 1, 10]
fits_nb = {}
nb_data = {}
for phi in phi_grid:
yy = rnegbin_mu_phi(rng, mu, phi)
d = pd.DataFrame({"x": x, "y": yy})
nb_data[phi] = d
fits_nb[phi] = smf.glm("y ~ x", data=d, family=sm.families.NegativeBinomial(alpha=1 / phi)).fit()
pd.DataFrame({phi: fits_nb[phi].params for phi in phi_grid}).T.rename_axis("phi")| Intercept | x | |
|---|---|---|
| phi | ||
| 0.1 | 0.764097 | 1.744021 |
| 1.0 | 1.017681 | 1.945912 |
| 10.0 | 0.865666 | 2.165113 |
fig, axes = plt.subplots(1, 3, figsize=(12, 3.5), sharey=True)
for ax, phi in zip(axes, phi_grid):
d = nb_data[phi]
fit = fits_nb[phi]
ax.plot(xgrid, np.exp(fit.params["Intercept"] + fit.params["x"] * xgrid), color="black")
ax.scatter(d.x, d.y, s=22, alpha=0.75)
ax.set_title(rf"$\phi={phi}$")
ax.set_xlabel("x")
ax.set_ylim(-1, 200)
axes[0].set_ylabel("y")
fig.suptitle("Simulated overdispersed Poisson / negative-binomial regressions")Text(0.5, 0.98, 'Simulated overdispersed Poisson / negative-binomial regressions')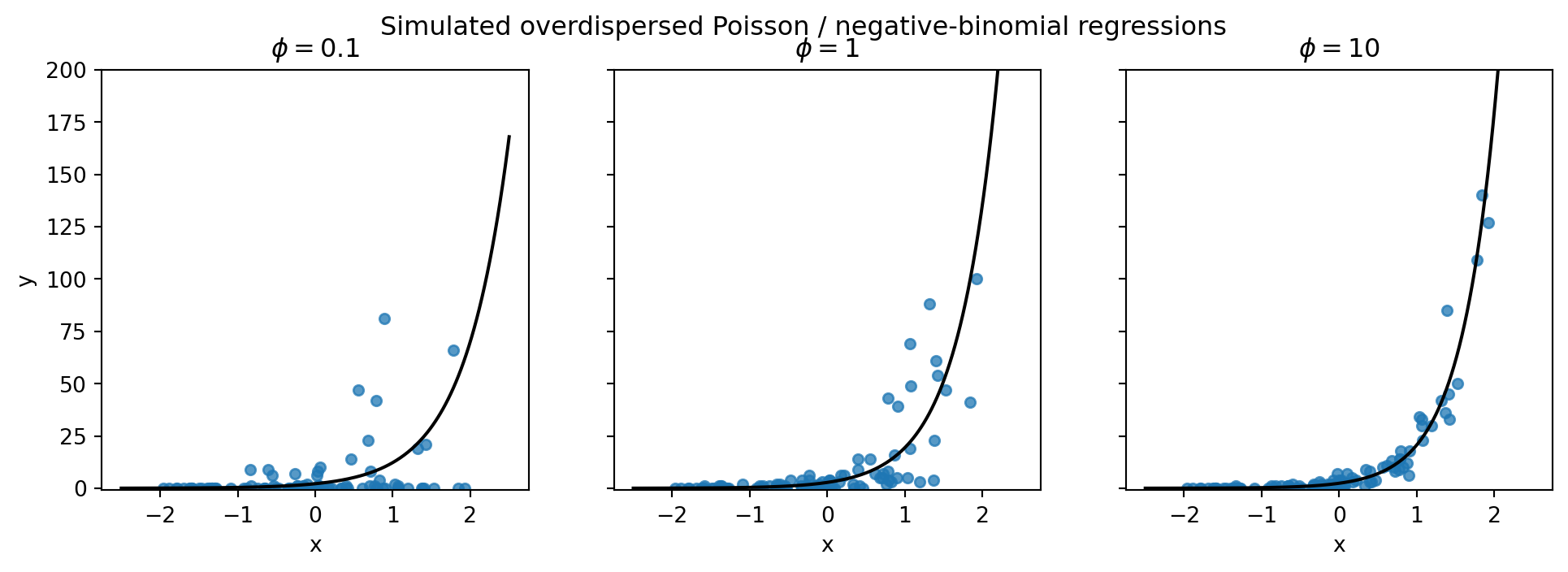
A useful diagnostic is to fit a Poisson model to negative-binomial data and compare the Pearson dispersion statistic to 1.
rows = []
for phi, d in nb_data.items():
poisson_fit = smf.glm("y ~ x", data=d, family=sm.families.Poisson()).fit()
pearson_dispersion = poisson_fit.pearson_chi2 / poisson_fit.df_resid
rows.append({
"phi": phi,
"poisson_intercept": poisson_fit.params["Intercept"],
"poisson_x": poisson_fit.params["x"],
"pearson_dispersion": pearson_dispersion,
})
pd.DataFrame(rows)| phi | poisson_intercept | poisson_x | pearson_dispersion | |
|---|---|---|---|---|
| 0 | 0.1 | 0.980643 | 1.129890 | 19.498917 |
| 1 | 1.0 | 0.996134 | 2.018917 | 7.267926 |
| 2 | 10.0 | 0.900847 | 2.125748 | 1.391068 |
Poisson regression:
from pathlib import Path
from cmdstanpy import CmdStanModel
poisson_stan = """
data {
int<lower=1> N;
vector[N] x;
array[N] int<lower=0> y;
}
parameters {
real alpha;
real beta;
}
model {
alpha ~ normal(0, 5);
beta ~ normal(0, 5);
y ~ poisson_log(alpha + beta * x);
}
generated quantities {
array[N] int y_rep;
for (n in 1:N) y_rep[n] = poisson_log_rng(alpha + beta * x[n]);
}
"""
Path("poisson_regression.stan").write_text(poisson_stan)
model = CmdStanModel(stan_file="poisson_regression.stan")
fit = model.sample(data={"N": n, "x": x, "y": y.astype(int)}, seed=3579)
fit.summary().loc[["alpha", "beta"]]Negative-binomial regression with Stan’s neg_binomial_2_log, where phi is the overdispersion parameter:
nb_stan = """
data {
int<lower=1> N;
vector[N] x;
array[N] int<lower=0> y;
}
parameters {
real alpha;
real beta;
real<lower=0> phi;
}
model {
alpha ~ normal(0, 5);
beta ~ normal(0, 5);
phi ~ exponential(1);
y ~ neg_binomial_2_log(alpha + beta * x, phi);
}
"""
Path("neg_binomial_regression.stan").write_text(nb_stan)
model_nb = CmdStanModel(stan_file="neg_binomial_regression.stan")
fit_nb = model_nb.sample(data={"N": n, "x": x, "y": nb_data[1].y.astype(int).to_numpy()}, seed=3579)
fit_nb.summary().loc[["alpha", "beta", "phi"]]