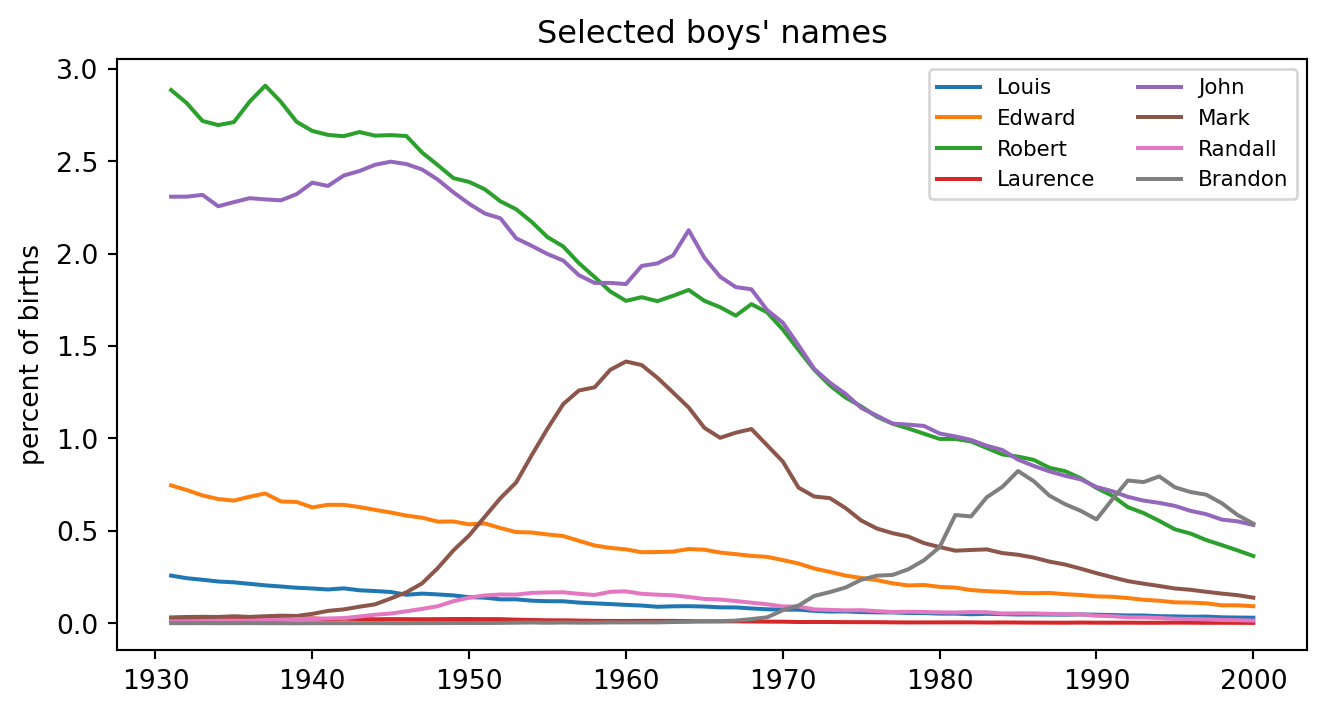
This page ports the core name-statistics workflow: normalize name counts by year, compute timing/popularity/volatility summaries, and display selected names ordered by peak year.
Code
from pathlib import Pathimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.api as smroot = Path("../../ROS-Examples")allnames = pd.read_csv(root /"Names/data/allnames_clean.csv")allnames.head()
X
name
sex
X1880
X1881
X1882
X1883
X1884
X1885
X1886
...
X2001
X2002
X2003
X2004
X2005
X2006
X2007
X2008
X2009
X2010
0
1
Mary
F
7065
6919
8149
8012
9217
9128
9891
...
5715
5439
4996
4792
4439
4073
3665
3478
3132
2826
1
2
Anna
F
2604
2698
3143
3306
3860
3994
4283
...
10564
10372
9429
9510
9085
8590
7866
7236
6755
6242
2
3
Emma
F
2003
2034
2303
2367
2587
2728
2764
...
13299
16520
22690
21591
20318
19092
18338
18765
17830
17179
3
4
Elizabeth
F
1939
1852
2187
2255
2549
2582
2680
...
14767
14581
14083
13536
12705
12397
13013
11956
10969
10135
4
5
Minnie
F
1746
1653
2004
2035
2243
2178
2372
...
25
33
25
26
31
37
17
43
28
37
5 rows × 134 columns
Normalize counts by year
Code
years = np.arange(1931, 2001)year_cols = [f"X{y}"for y in years]counts = allnames[year_cols].to_numpy(dtype=float)counts_norm = counts / counts.sum(axis=0, keepdims=True)counts_adj = np.where(counts ==0, 2, counts)counts_adj_norm = counts_adj / counts_adj.sum(axis=0, keepdims=True)