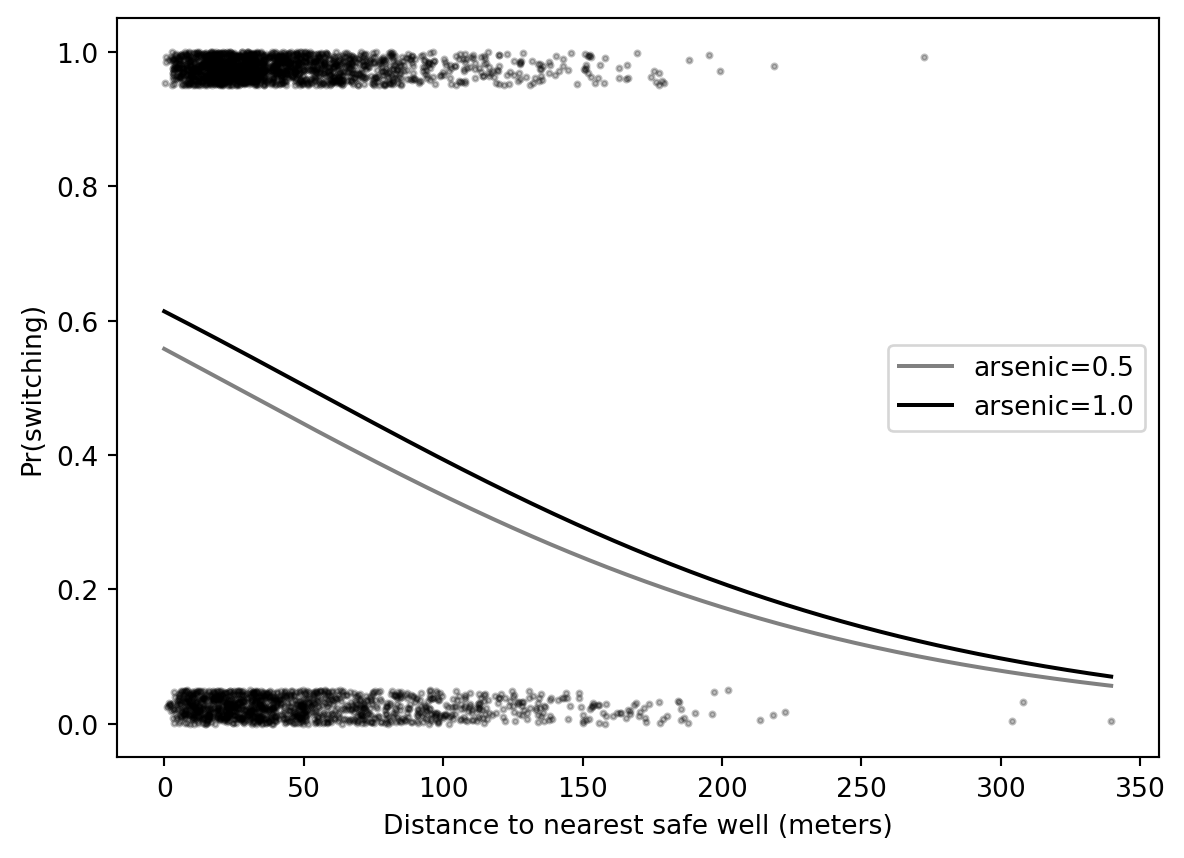
fig, ax = plt.subplots()ax.scatter(wells["dist"], y_jit, s=4, color="black", alpha=0.25)for a, color in [(0.5, "gray"), (1.0, "black")]: p = expit(fit_3.params["Intercept"] + fit_3.params["dist100"]*xs/100+ fit_3.params["arsenic"]*a) ax.plot(xs, p, color=color, label=f"arsenic={a}")ax.legend()ax.set_xlabel("Distance to nearest safe well (meters)")ax.set_ylabel("Pr(switching)")
BlackJAX is useful if comparing NUTS behavior, priors under separation, or custom PSIS/LOO workflows. For ordinary model-building exposition, CmdStanPy/PyMC are clearer.
Source Code
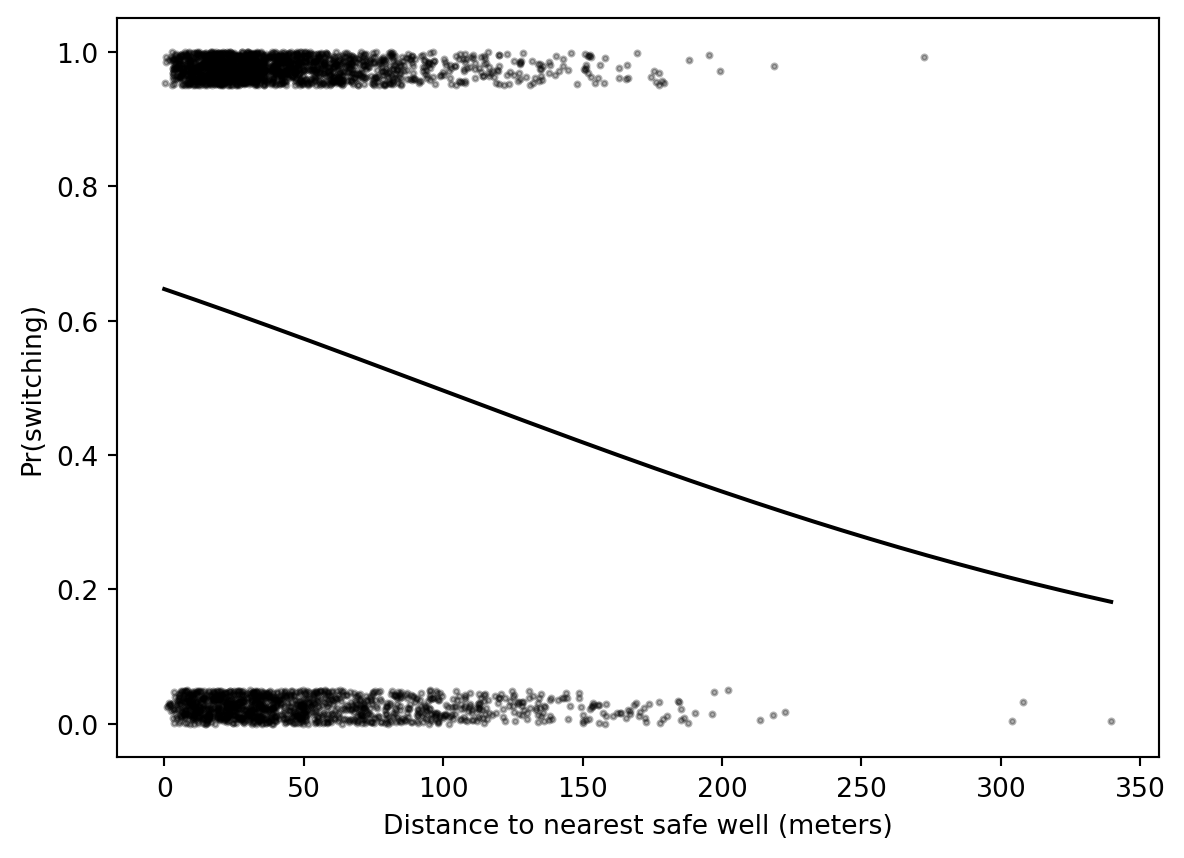
# Arsenic wells: building logistic regression modelsSource: `Arsenic/arsenic_logistic_building.Rmd`This ports the core model-building sequence for the Bangladesh wells example.## Load data```{python}from pathlib import Pathimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.formula.api as smffrom scipy.special import expitroot = Path("../../ROS-Examples")wells = pd.read_csv(root /"Arsenic/data/wells.csv")wells["dist100"] = wells["dist"] /100wells.head()```## Null-model log scores```{python}y = wells["switch"].to_numpy()for p in [0.5, y.mean()]: log_score = np.sum(y*np.log(p) + (1-y)*np.log(1-p))print(round(p, 3), round(log_score, 1))```## Single predictor: distanceR original:```rstan_glm(switch~ dist100, family =binomial(link ="logit"), data=wells)```Python frequentist analog:```{python}fit_2 = smf.logit("switch ~ dist100", data=wells).fit()fit_2.params``````{python}fig, ax = plt.subplots()rng = np.random.default_rng(123)y_jit = y + (1-2*y) * rng.uniform(0, 0.05, size=len(y))ax.scatter(wells["dist"], y_jit, s=4, color="black", alpha=0.3)xs = np.linspace(0, wells["dist"].max(), 300)ax.plot(xs, expit(fit_2.params["Intercept"] + fit_2.params["dist100"] * xs/100), color="black")ax.set_xlabel("Distance to nearest safe well (meters)")ax.set_ylabel("Pr(switching)")```## Two predictors: distance + arsenic```{python}fit_3 = smf.logit("switch ~ dist100 + arsenic", data=wells).fit()fit_3.params```Compare predicted curves at fixed arsenic levels:```{python}fig, ax = plt.subplots()ax.scatter(wells["dist"], y_jit, s=4, color="black", alpha=0.25)for a, color in [(0.5, "gray"), (1.0, "black")]: p = expit(fit_3.params["Intercept"] + fit_3.params["dist100"]*xs/100+ fit_3.params["arsenic"]*a) ax.plot(xs, p, color=color, label=f"arsenic={a}")ax.legend()ax.set_xlabel("Distance to nearest safe well (meters)")ax.set_ylabel("Pr(switching)")```## Interaction```{python}fit_4 = smf.logit("switch ~ dist100 * arsenic", data=wells).fit()fit_4.params```## CmdStanPy equivalentFor a Bayesian analog, use Bernoulli-logit regression:```standata { int<lower=1> N; int<lower=1> K; matrix[N, K] X; array[N] int<lower=0,upper=1> y;}parameters { vector[K] beta;}model { beta ~ normal(0, 2.5); y ~ bernoulli_logit(X * beta);}```## BlackJAX relevanceThis is a clean example for a hand-written logistic-regression log density:```pythonlog_lik =sum(y * log_sigmoid(X @ beta) + (1-y) * log_sigmoid(-(X @ beta)))log_prior =sum(norm.logpdf(beta, 0, 2.5))```BlackJAX is useful if comparing NUTS behavior, priors under separation, or custom PSIS/LOO workflows. For ordinary model-building exposition, CmdStanPy/PyMC are clearer.