This page ports the core rstanarm::stan_glm examples to Python. The classical fit uses statsmodels; the Bayesian version uses CmdStanPy with weakly informative priors.
Load data
Code
from pathlib import Pathimport pandas as pdimport numpy as npimport statsmodels.formula.api as smfimport matplotlib.pyplot as pltroot = Path("../../ROS-Examples")kidiq = pd.read_csv(root /"KidIQ/data/kidiq.csv")kidiq.head()
# Build X with intercept, mom_hs, mom_iq and sample using CmdStanPy.# This is the CmdStanPy replacement for rstanarm::stan_glm(kid_score ~ mom_hs + mom_iq).
BlackJAX relevance
This example is a good teaching case for writing the Gaussian regression log density by hand, but CmdStanPy or statsmodels is preferable for the main exposition. BlackJAX becomes useful when we want explicit NUTS mechanics or JAX-vectorized repeated simulations.
Source Code
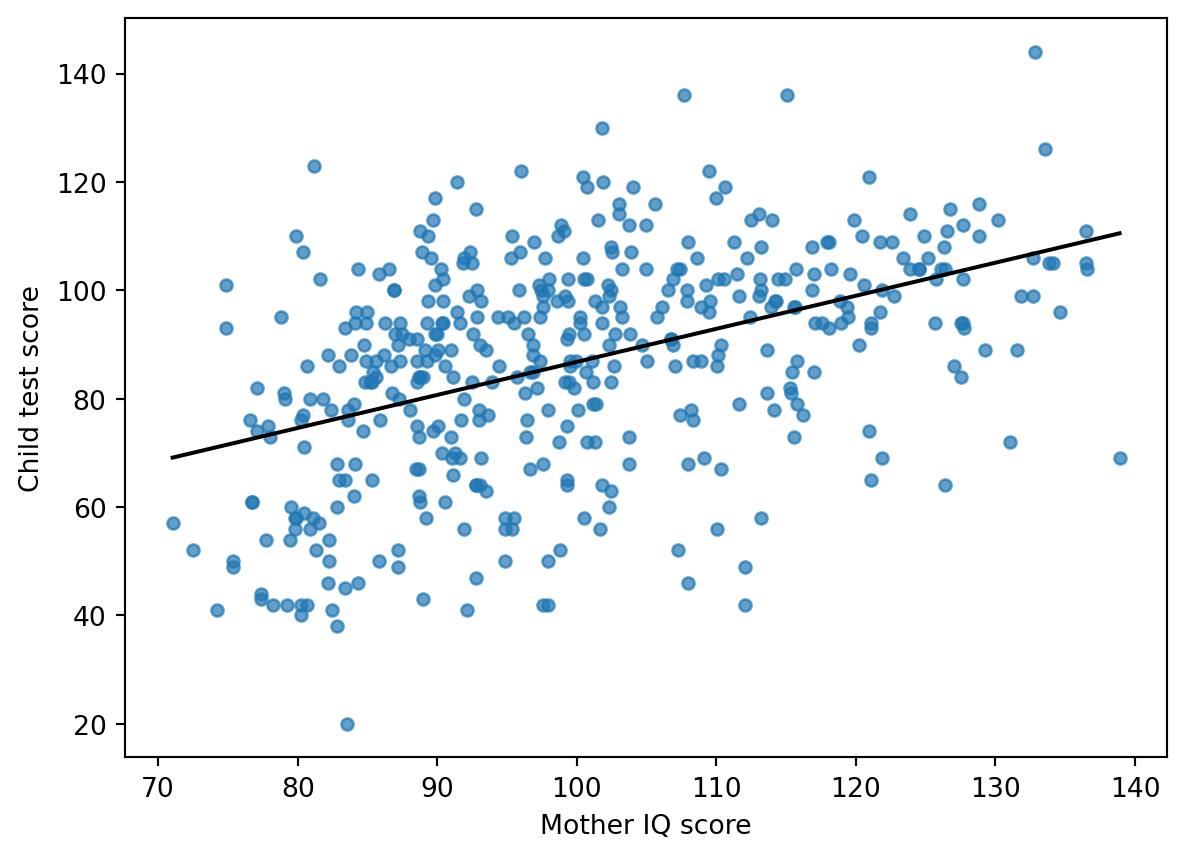
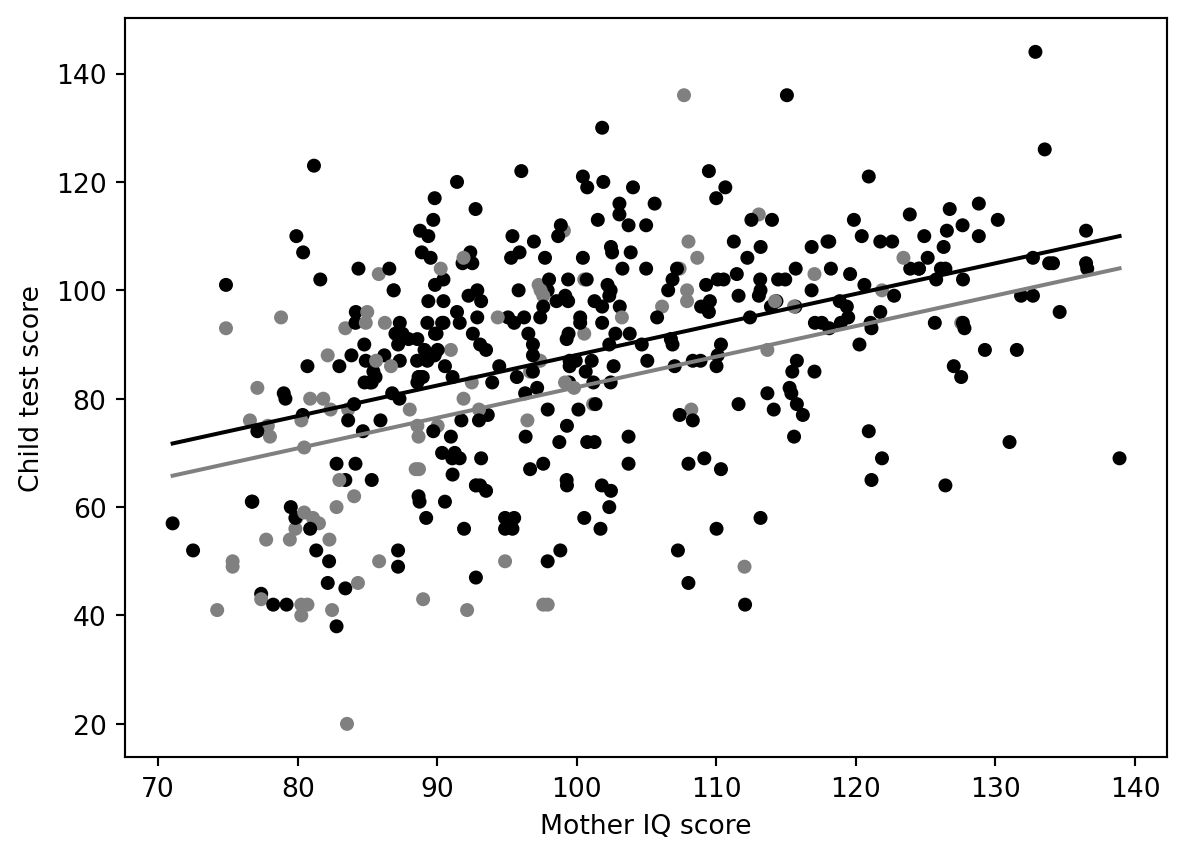
# KidIQ: multiple linear regressionSource: `KidIQ/kidiq.Rmd`This page ports the core `rstanarm::stan_glm` examples to Python. The classical fit uses `statsmodels`; the Bayesian version uses CmdStanPy with weakly informative priors.## Load data```{python}from pathlib import Pathimport pandas as pdimport numpy as npimport statsmodels.formula.api as smfimport matplotlib.pyplot as pltroot = Path("../../ROS-Examples")kidiq = pd.read_csv(root /"KidIQ/data/kidiq.csv")kidiq.head()```## Single binary predictorR original:```rstan_glm(kid_score ~ mom_hs, data=kidiq)```Python:```{python}fit_1 = smf.ols("kid_score ~ mom_hs", data=kidiq).fit()fit_1.summary()```## Single continuous predictor```{python}fit_2 = smf.ols("kid_score ~ mom_iq", data=kidiq).fit()fit_2.params``````{python}ax = kidiq.plot.scatter("mom_iq", "kid_score", alpha=0.7)xs = np.linspace(kidiq.mom_iq.min(), kidiq.mom_iq.max(), 100)ax.plot(xs, fit_2.params["Intercept"] + fit_2.params["mom_iq"] * xs, color="black")ax.set_xlabel("Mother IQ score")ax.set_ylabel("Child test score")```## Two predictors```{python}fit_3 = smf.ols("kid_score ~ mom_hs + mom_iq", data=kidiq).fit()fit_3.params```Two fitted lines, no interaction:```{python}fig, ax = plt.subplots()colors = np.where(kidiq.mom_hs ==1, "black", "gray")ax.scatter(kidiq.mom_iq, kidiq.kid_score, c=colors, s=18)for hs, color in [(0, "gray"), (1, "black")]: ax.plot(xs, fit_3.params["Intercept"] + fit_3.params["mom_hs"]*hs + fit_3.params["mom_iq"]*xs, color=color)ax.set_xlabel("Mother IQ score")ax.set_ylabel("Child test score")```## Interaction model```{python}fit_4 = smf.ols("kid_score ~ mom_hs * mom_iq", data=kidiq).fit()fit_4.params```## CmdStanPy equivalentFor a direct Bayesian analog to `stan_glm`, use a Gaussian regression with weak priors.```standata { int<lower=1> N; int<lower=1> K; matrix[N, K] X; vector[N] y;}parameters { vector[K] beta; real<lower=0> sigma;}model { beta ~ normal(0, 10); sigma ~ exponential(1); y ~ normal(X * beta, sigma);}``````{python}# Build X with intercept, mom_hs, mom_iq and sample using CmdStanPy.# This is the CmdStanPy replacement for rstanarm::stan_glm(kid_score ~ mom_hs + mom_iq).```## BlackJAX relevanceThis example is a good teaching case for writing the Gaussian regression log density by hand, but CmdStanPy or statsmodels is preferable for the main exposition. BlackJAX becomes useful when we want explicit NUTS mechanics or JAX-vectorized repeated simulations.