# KidIQ leave-one-out cross-validation
Source: `KidIQ/kidiq_loo.Rmd`
This page ports the ROS leave-one-out example to Python. The goal is to show why in-sample log scores can reward unnecessary predictors, while PSIS-LOO estimates predictive accuracy more honestly.
## Setup and data
```{python}
from pathlib import Path
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import patsy
root = Path("../../ROS-Examples")
kidiq = pd.read_csv(root / "KidIQ/data/kidiq.csv")
SEED = 1507
kidiq.head()
```
## Linear regression with two predictors
```{python}
fit_3_ols = smf.ols("kid_score ~ mom_hs + mom_iq", data=kidiq).fit()
fit_3_ols.summary()
```
### Plug-in in-sample log score
This mirrors the R calculation `sum(dnorm(y, fitted(fit), sigma(fit), log=TRUE))`, using fitted mean parameters and residual scale.
```{python}
from scipy.stats import norm
pluginlogscore_3 = norm.logpdf(kidiq.kid_score, loc=fit_3_ols.fittedvalues, scale=np.sqrt(fit_3_ols.scale)).sum()
round(pluginlogscore_3, 1)
```
## Bayesian fit with CmdStanPy
We use a Gaussian regression with weak priors and generated `log_lik` so ArviZ can compute PSIS-LOO.
```{python}
from cmdstanpy import CmdStanModel
import arviz as az
stan_dir = Path("_generated_stan")
stan_dir.mkdir(exist_ok=True)
stan_file = stan_dir / "kid_iq_gaussian_lm.stan"
stan_file.write_text(r'''
data {
int<lower=1> N;
int<lower=1> K;
matrix[N, K] X;
vector[N] y;
}
parameters {
vector[K] beta;
real<lower=0> sigma;
}
model {
beta ~ normal(0, 20);
sigma ~ exponential(1.0 / 30);
y ~ normal(X * beta, sigma);
}
generated quantities {
vector[N] log_lik;
vector[N] mu;
mu = X * beta;
for (n in 1:N) log_lik[n] = normal_lpdf(y[n] | mu[n], sigma);
}
''')
model = CmdStanModel(stan_file=str(stan_file))
def design(formula, data):
y, X = patsy.dmatrices(formula, data, return_type="dataframe")
return np.asarray(y).ravel(), X
def sample_lm(formula, data, seed=SEED):
y, X = design(formula, data)
fit = model.sample(
data={"N": len(y), "K": X.shape[1], "X": X.to_numpy(), "y": y},
seed=seed, chains=4, parallel_chains=4, show_progress=False,
)
return fit, X, y
fit_3, X_3, y = sample_lm("kid_score ~ mom_hs + mom_iq", kidiq)
```
### In-sample posterior predictive log score
Instead of plugging in one fitted mean and one sigma, this integrates over posterior draws:
```{python}
def draws_matrix(fit, X):
draws = fit.draws_pd()
beta_cols = [f"beta[{i}]" for i in range(1, X.shape[1] + 1)]
beta = draws[beta_cols].to_numpy()
sigma = draws["sigma"].to_numpy()
mu = beta @ X.to_numpy().T
return mu, sigma
def posterior_predictive_logscore(fit, X, y):
mu, sigma = draws_matrix(fit, X)
dens = norm.pdf(y[None, :], loc=mu, scale=sigma[:, None])
return np.log(dens.mean(axis=0)).sum()
logscore_3 = posterior_predictive_logscore(fit_3, X_3, y)
round(logscore_3, 1)
```
## Add five pure-noise predictors
```{python}
rng = np.random.default_rng(SEED)
kidiqr = kidiq.copy()
for j in range(1, 6):
kidiqr[f"noise{j}"] = rng.normal(size=len(kidiqr))
noise_terms = " + ".join([f"noise{j}" for j in range(1, 6)])
formula_3n = f"kid_score ~ mom_hs + mom_iq + {noise_terms}"
fit_3n_ols = smf.ols(formula_3n, data=kidiqr).fit()
pluginlogscore_3n = norm.logpdf(kidiq.kid_score, loc=fit_3n_ols.fittedvalues, scale=np.sqrt(fit_3n_ols.scale)).sum()
fit_3n, X_3n, _ = sample_lm(formula_3n, kidiqr, seed=SEED + 1)
logscore_3n = posterior_predictive_logscore(fit_3n, X_3n, y)
round(pluginlogscore_3n, 1), round(logscore_3n, 1)
```
```{python}
print("plug-in improvement:", round(pluginlogscore_3n - pluginlogscore_3, 1))
print("posterior predictive improvement:", round(logscore_3n - logscore_3, 1))
```
The in-sample scores can look better after adding pure noise because they evaluate the same data used to fit the extra coefficients.
## Compare models with PSIS-LOO
```{python}
idata_3 = az.from_cmdstanpy(posterior=fit_3, log_likelihood="log_lik")
idata_3n = az.from_cmdstanpy(posterior=fit_3n, log_likelihood="log_lik")
loo_3 = az.loo(idata_3)
loo_3n = az.loo(idata_3n)
print(loo_3)
print(loo_3n)
az.compare({"mom_hs + mom_iq": idata_3, "+ five noise predictors": idata_3n}, ic="loo")
```
## Other predictor sets
The R page also compares a single-predictor model, an interaction, and a log-transformed interaction.
```{python}
fit_1, X_1, _ = sample_lm("kid_score ~ mom_hs", kidiq, seed=SEED + 2)
fit_4, X_4, _ = sample_lm("kid_score ~ mom_hs + mom_iq + mom_iq:mom_hs", kidiq, seed=SEED + 3)
fit_5, X_5, _ = sample_lm("kid_score ~ mom_hs + np.log(mom_iq) + np.log(mom_iq):mom_hs", kidiq, seed=SEED + 4)
idata_1 = az.from_cmdstanpy(posterior=fit_1, log_likelihood="log_lik")
idata_4 = az.from_cmdstanpy(posterior=fit_4, log_likelihood="log_lik")
idata_5 = az.from_cmdstanpy(posterior=fit_5, log_likelihood="log_lik")
az.compare({
"mom_hs": idata_1,
"mom_hs + mom_iq": idata_3,
"+ interaction": idata_4,
"log(mom_iq) interaction": idata_5,
}, ic="loo")
```
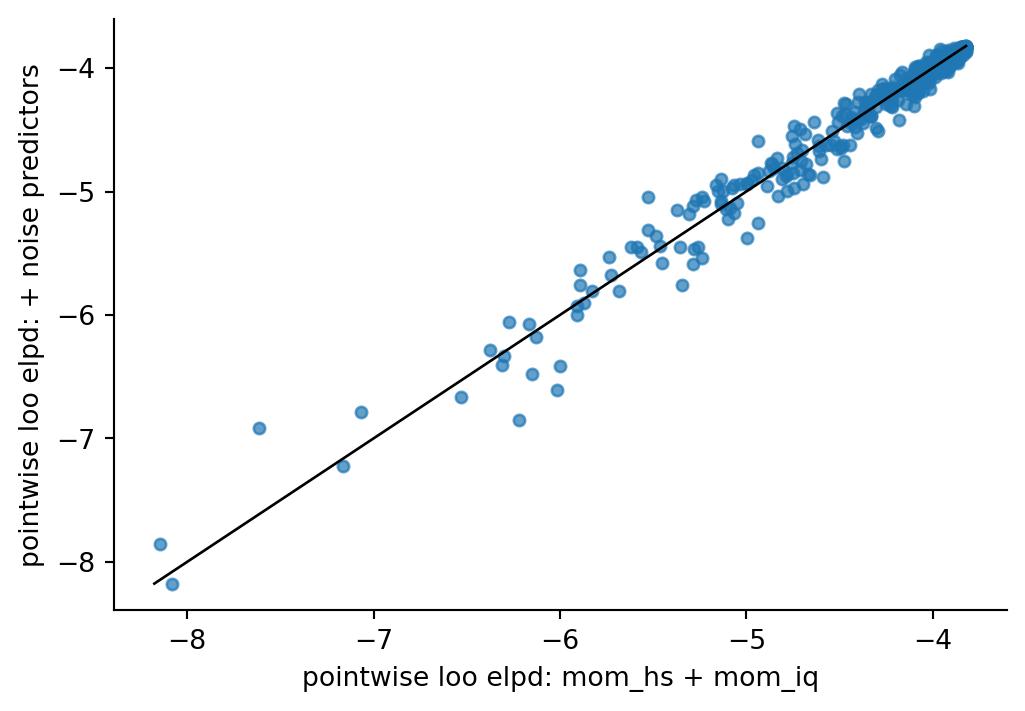
## Visual check of pointwise LOO influence
```{python}
import matplotlib.pyplot as plt
loo_i_3 = az.loo(idata_3, pointwise=True).loo_i.values
loo_i_3n = az.loo(idata_3n, pointwise=True).loo_i.values
fig, ax = plt.subplots(figsize=(6, 4))
ax.scatter(loo_i_3, loo_i_3n, s=18, alpha=0.7)
lims = [min(loo_i_3.min(), loo_i_3n.min()), max(loo_i_3.max(), loo_i_3n.max())]
ax.plot(lims, lims, color="black", lw=1)
ax.set(xlabel="pointwise loo elpd: mom_hs + mom_iq", ylabel="pointwise loo elpd: + noise predictors")
ax.spines[["top", "right"]].set_visible(False)
```
## BlackJAX log-density sketch
For custom diagnostics or alternative samplers, the Gaussian regression log density can be written directly.
```{python}
from scipy.stats import norm
X_np = X_3.to_numpy()
y_np = np.asarray(y)
def kid_iq_logdensity(params):
beta = np.asarray(params["beta"])
log_sigma = params["log_sigma"]
sigma = np.exp(log_sigma)
mu = X_np @ beta
ll = np.sum(norm.logpdf(y_np, mu, sigma))
prior_beta = np.sum(norm.logpdf(beta, 0, 20))
prior_sigma = np.log(1 / 30) - sigma / 30 + log_sigma
return ll + prior_beta + prior_sigma
kid_iq_logdensity({"beta": np.zeros(X_np.shape[1]), "log_sigma": np.log(np.std(y_np))})
```