# Electric Company / treatment effects
Source: `ElectricCompany/electric.Rmd`
The electric-company example studies paired classes with pre-test and post-test scores. Each row in the wide data contains a treated class and a matched control class. The original R page uses `rstanarm::stan_glm`; here the core workflow is reproduced with `pandas`, `statsmodels`, and plotting code, using a lightweight Bayesian linear-regression helper where the page needs posterior draws.
## Setup and wide data
```{python}
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
from python.bayes_glm import bayes_lm
def ros_root():
candidates = [
Path("../../ROS-Examples"),
Path("../ROS-Examples"),
Path("/Users/alal/tmp/ros-python-book/ROS-Examples"),
]
for candidate in candidates:
if candidate.exists():
return candidate
return candidates[0]
root = ros_root()
electric_wide = pd.read_table(root / "ElectricCompany/data/electric_wide.txt", sep=r"\s+")
electric_wide.head()
```
```{python}
score_cols = ["treated_pretest", "treated_posttest", "control_pretest", "control_posttest"]
electric_wide.groupby("grade")[score_cols].agg(["mean", "std", "count"])
```
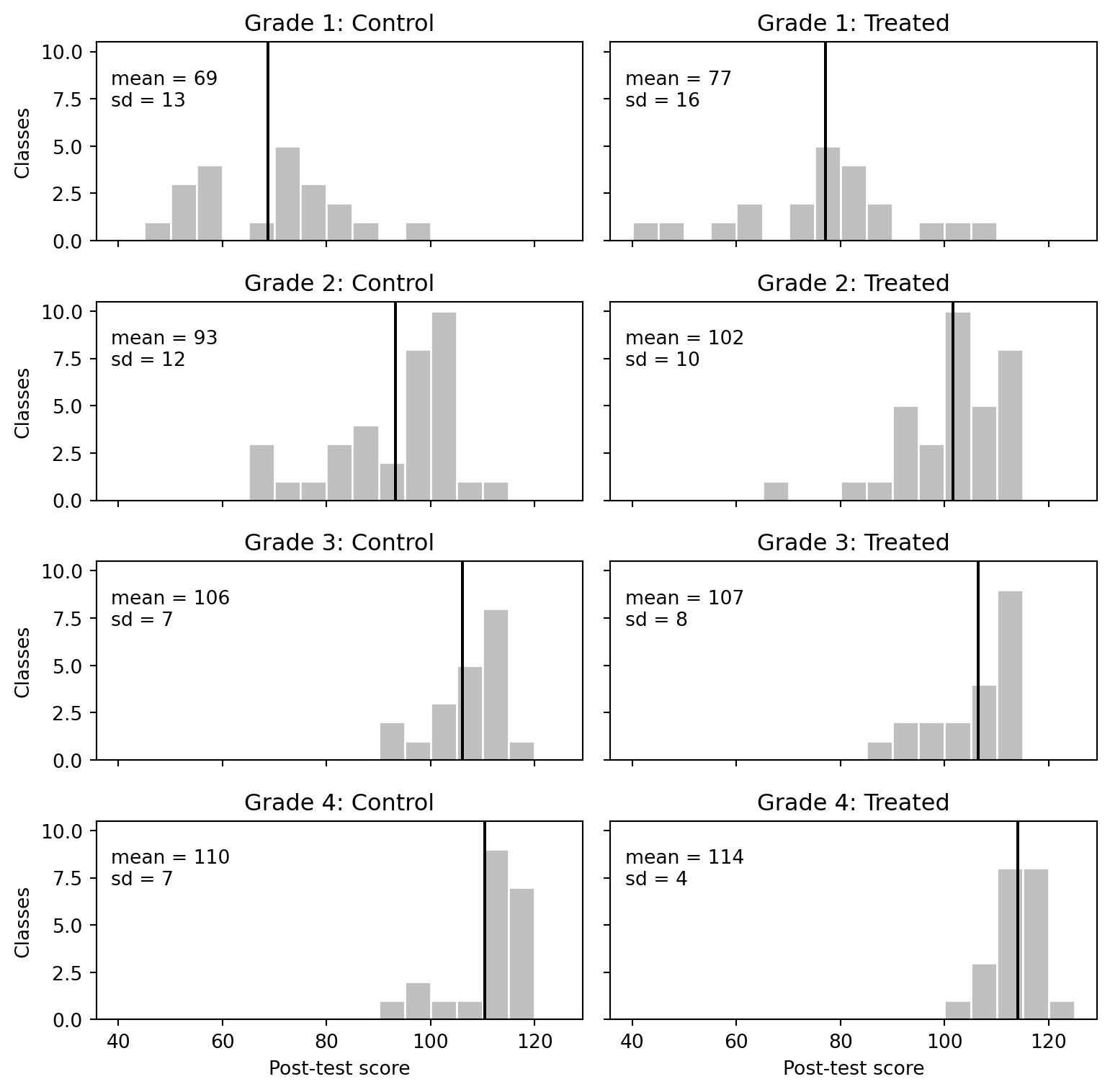
## Histograms of post-test scores by grade
```{python}
fig, axes = plt.subplots(4, 2, figsize=(8, 8), sharex=True, sharey=True)
bins = np.arange(40, 130, 5)
for row, grade in enumerate(range(1, 5)):
d = electric_wide[electric_wide["grade"] == grade]
for col, arm, title in [(0, "control_posttest", "Control"), (1, "treated_posttest", "Treated")]:
ax = axes[row, col]
ax.hist(d[arm], bins=bins, color="0.75", edgecolor="white")
ax.axvline(d[arm].mean(), color="black", linewidth=1.5)
ax.text(0.03, 0.86, f"mean = {d[arm].mean():.0f}\nsd = {d[arm].std():.0f}", transform=ax.transAxes, va="top")
ax.set_title(f"Grade {grade}: {title}")
if row == 3:
ax.set_xlabel("Post-test score")
if col == 0:
ax.set_ylabel("Classes")
fig.tight_layout()
```
## Convert to long paired-class data
```{python}
treated = electric_wide[["city", "grade", "treated_pretest", "treated_posttest", "supplement"]].rename(
columns={"treated_pretest": "pre_test", "treated_posttest": "post_test"}
)
treated["treatment"] = 1
treated["supp"] = (treated["supplement"] == "Supplement").astype(float)
control = electric_wide[["city", "grade", "control_pretest", "control_posttest"]].rename(
columns={"control_pretest": "pre_test", "control_posttest": "post_test"}
)
control["treatment"] = 0
control["supplement"] = pd.NA
control["supp"] = np.nan
electric = pd.concat([treated, control], ignore_index=True)
electric["pair_id"] = np.tile(np.arange(len(electric_wide)), 2)
electric.head()
```
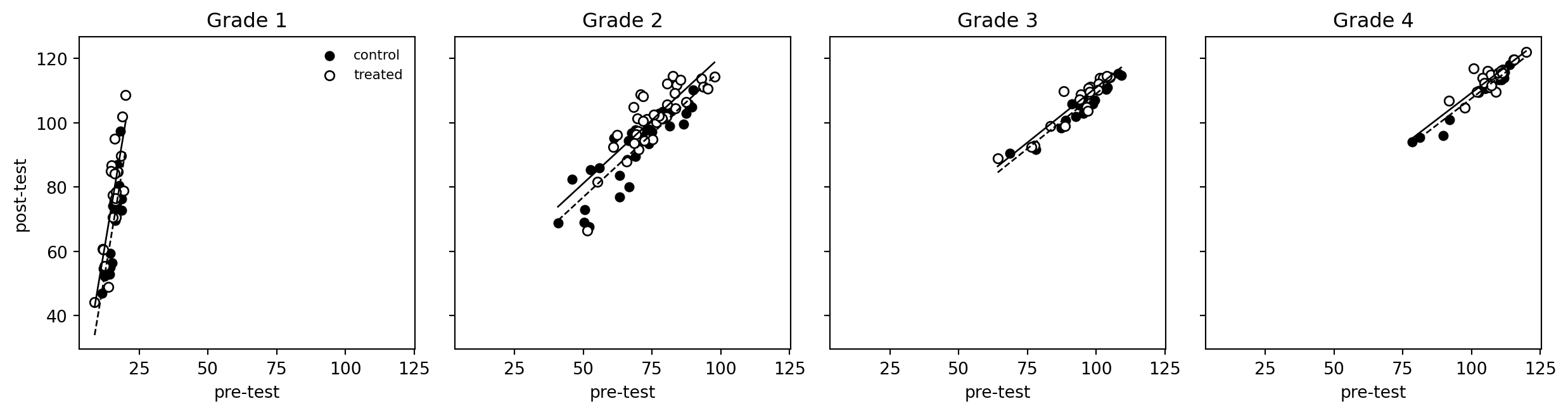
## Scatterplots and parallel regression lines
For each grade, the R page overlays regression lines for treated and control classes. The first model uses a common pre-test slope and a treatment intercept shift.
```{python}
fig, axes = plt.subplots(1, 4, figsize=(13, 3.5), sharex=True, sharey=True)
for ax, grade in zip(axes, range(1, 5)):
d = electric[electric["grade"] == grade]
fit = smf.ols("post_test ~ pre_test + treatment", data=d).fit()
xs = np.linspace(d["pre_test"].min(), d["pre_test"].max(), 100)
control_line = fit.params["Intercept"] + fit.params["pre_test"] * xs
treated_line = control_line + fit.params["treatment"]
ax.scatter(d.loc[d.treatment == 0, "pre_test"], d.loc[d.treatment == 0, "post_test"], color="black", s=25, label="control")
ax.scatter(d.loc[d.treatment == 1, "pre_test"], d.loc[d.treatment == 1, "post_test"], facecolors="white", edgecolors="black", s=30, label="treated")
ax.plot(xs, control_line, color="black", linestyle="--", linewidth=1)
ax.plot(xs, treated_line, color="black", linewidth=1)
ax.set_title(f"Grade {grade}")
ax.set_xlabel("pre-test")
axes[0].set_ylabel("post-test")
axes[0].legend(frameon=False, fontsize=8)
fig.tight_layout()
```
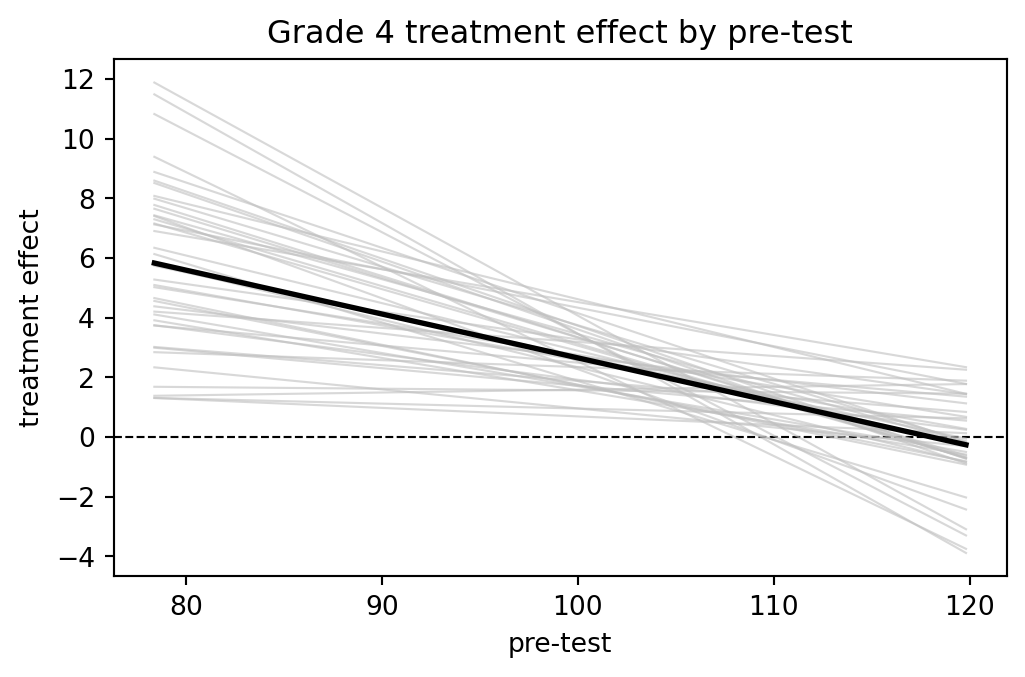
## Treatment-by-pretest interaction in grade 4
```{python}
grade4 = electric[electric["grade"] == 4].copy()
fit_g4 = smf.ols("post_test ~ treatment * pre_test", data=grade4).fit()
fit_g4_bayes = bayes_lm("post_test ~ treatment * pre_test", data=grade4, draws=1000, prior_scale=10.0, seed=4020)
fit_g4.summary()
```
The treatment effect at a given pre-test score is `treatment + treatment:pre_test * pre_test`.
```{python}
rng = np.random.default_rng(4020)
beta_draws = fit_g4_bayes.beta_draws
param_names = fit_g4_bayes.coef_names
it = param_names.index("treatment")
ii = param_names.index("treatment:pre_test")
xs = np.linspace(grade4["pre_test"].min(), grade4["pre_test"].max(), 100)
effect_draws = beta_draws[:, it, None] + beta_draws[:, ii, None] * xs
mean_effect_by_draw = beta_draws[:, it, None] + beta_draws[:, ii, None] * grade4["pre_test"].to_numpy()
fig, ax = plt.subplots(figsize=(6, 3.5))
ax.axhline(0, color="black", linestyle="--", linewidth=0.8)
for draw in effect_draws[:40]:
ax.plot(xs, draw, color="0.75", linewidth=0.8, alpha=0.6)
ax.plot(xs, fit_g4.params["treatment"] + fit_g4.params["treatment:pre_test"] * xs, color="black", linewidth=2)
ax.set_xlabel("pre-test")
ax.set_ylabel("treatment effect")
ax.set_title("Grade 4 treatment effect by pre-test")
```
```{python}
pd.Series(mean_effect_by_draw.mean(axis=1), name="mean_grade4_effect").describe()
```
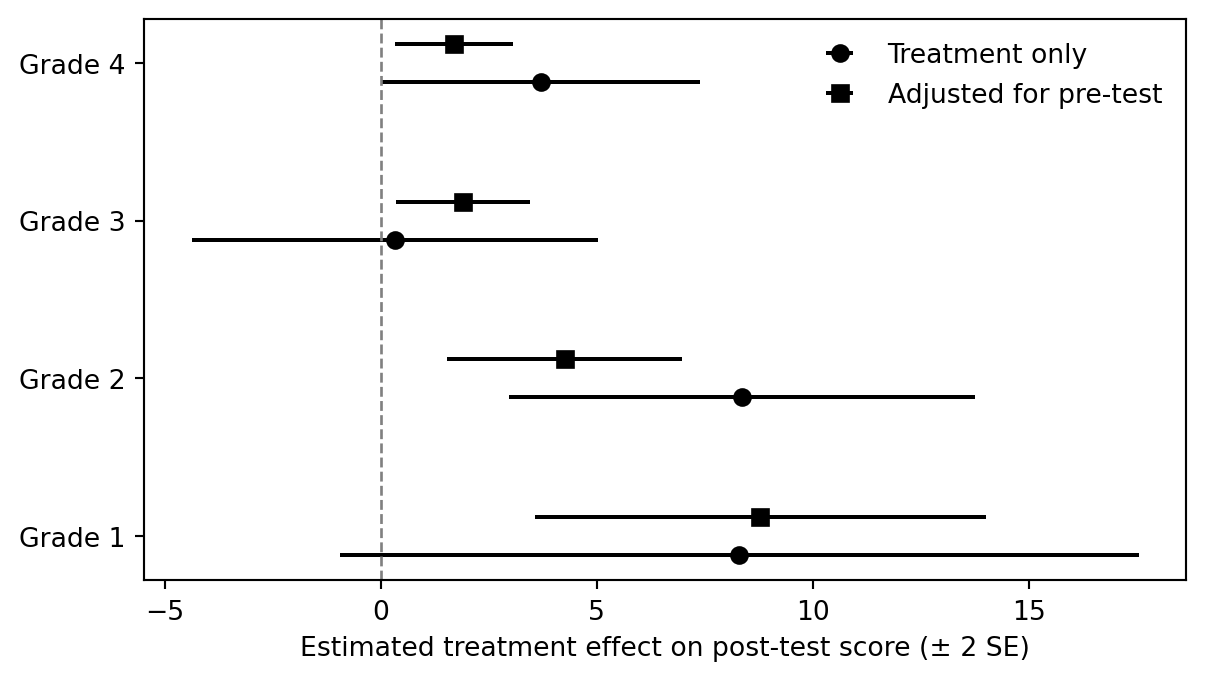
## Grade-specific treatment estimates
```{python}
rows = []
for grade in range(1, 5):
d = electric[electric["grade"] == grade]
simple = smf.ols("post_test ~ treatment", data=d).fit()
adjusted = smf.ols("post_test ~ treatment + pre_test", data=d).fit()
rows.append({
"grade": grade,
"simple_est": simple.params["treatment"],
"simple_se": simple.bse["treatment"],
"adjusted_est": adjusted.params["treatment"],
"adjusted_se": adjusted.bse["treatment"],
})
estimates = pd.DataFrame(rows)
estimates
```
```{python}
fig, ax = plt.subplots(figsize=(7, 3.8))
ypos = np.arange(len(estimates))
for offset, est_col, se_col, label, marker in [
(-0.12, "simple_est", "simple_se", "Treatment only", "o"),
(0.12, "adjusted_est", "adjusted_se", "Adjusted for pre-test", "s"),
]:
ax.errorbar(estimates[est_col], ypos + offset, xerr=2 * estimates[se_col], fmt=marker, color="black", capsize=0, label=label)
ax.axvline(0, color="0.5", linestyle="--", linewidth=1)
ax.set_yticks(ypos)
ax.set_yticklabels([f"Grade {g}" for g in estimates["grade"]])
ax.set_xlabel("Estimated treatment effect on post-test score (± 2 SE)")
ax.legend(frameon=False)
```
## Supplement versus replacement among treated classes
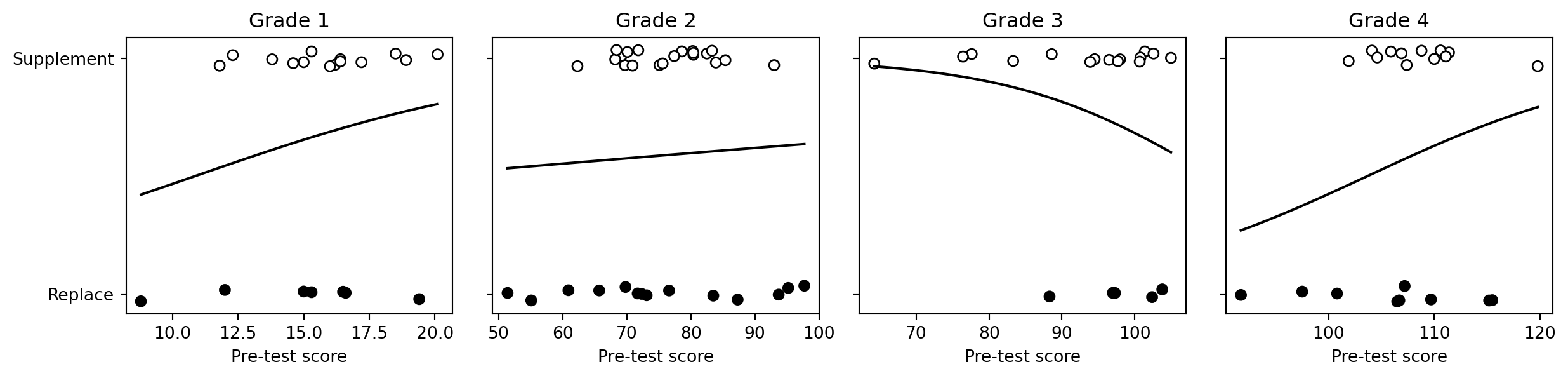
The treated arm has two variants: supplement and replacement. The R page first models supplement assignment as a function of pre-test score, then estimates the supplement effect on post-test score controlling for pre-test.
```{python}
def invlogit(x):
return 1 / (1 + np.exp(-x))
supp_rows = []
fig, axes = plt.subplots(1, 4, figsize=(13, 3.2), sharey=True)
for ax, grade in zip(axes, range(1, 5)):
d = electric[(electric["grade"] == grade) & electric["supp"].notna()].copy()
logit_fit = smf.logit("supp ~ pre_test", data=d).fit(disp=False)
outcome_fit = smf.ols("post_test ~ supp + pre_test", data=d).fit()
supp_rows.append({
"grade": grade,
"supp_assignment_slope": logit_fit.params["pre_test"],
"supp_effect_est": outcome_fit.params["supp"],
"supp_effect_se": outcome_fit.bse["supp"],
})
xs = np.linspace(d["pre_test"].min(), d["pre_test"].max(), 100)
probs = invlogit(logit_fit.params["Intercept"] + logit_fit.params["pre_test"] * xs)
jitter = rng.uniform(-0.035, 0.035, size=len(d))
ax.scatter(d["pre_test"], d["supp"] + jitter, facecolors=np.where(d["supp"] == 1, "white", "black"), edgecolors="black")
ax.plot(xs, probs, color="black")
ax.set_title(f"Grade {grade}")
ax.set_xlabel("Pre-test score")
axes[0].set_yticks([0, 1])
axes[0].set_yticklabels(["Replace", "Supplement"])
fig.tight_layout()
supp_estimates = pd.DataFrame(supp_rows)
supp_estimates
```
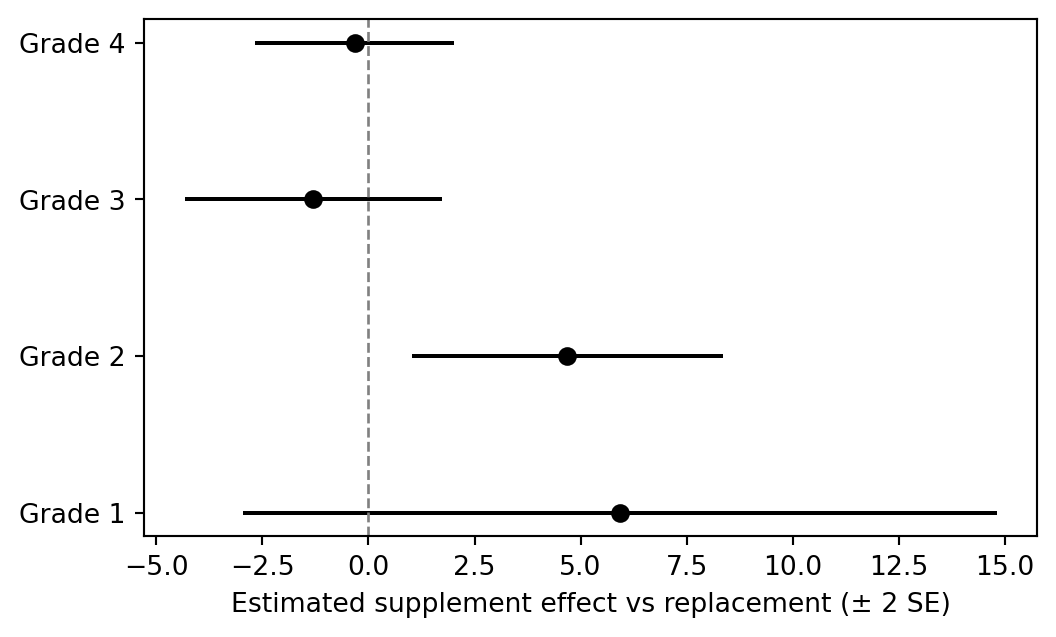
```{python}
fig, ax = plt.subplots(figsize=(6, 3.5))
ypos = np.arange(len(supp_estimates))
ax.errorbar(supp_estimates["supp_effect_est"], ypos, xerr=2 * supp_estimates["supp_effect_se"], fmt="o", color="black")
ax.axvline(0, color="0.5", linestyle="--", linewidth=1)
ax.set_yticks(ypos)
ax.set_yticklabels([f"Grade {g}" for g in supp_estimates["grade"]])
ax.set_xlabel("Estimated supplement effect vs replacement (± 2 SE)")
```
## CmdStanPy note
```{python}
#| eval: false
from cmdstanpy import CmdStanModel
# The rstanarm calls on the source page are Gaussian linear regressions and one
# logistic regression. CmdStanPy is most useful here if you want shared priors
# or a hierarchical model that partially pools treatment effects across grades.
```